System Architecture¶
Below are sections presenting details of the Enterprise Gateway internals and other related items.While we will attempt to maintain its consistency, the ultimate answers are in the code itself.
Enterprise Gateway Process Proxy Extensions¶
Enterprise Gateway is follow-on project to Jupyter Kernel Gateway with additional abilities to support
remote kernel sessions on behalf of multiple users within resource managed frameworks such as Yarn. Enterprise
Gateway introduces these capabilities by extending the existing class hierarchies for KernelManager,
MultiKernelManager and KernelSpec classes, along with an additional abstraction known as a
process proxy.
Overview¶
At its basic level, a running kernel consists of two components for its communication - a set of ports and a process.
Kernel Ports¶
The first component is a set of five zero-MQ ports used to convey the Jupyter protocol between the Notebook and the underlying kernel. In addition to the 5 ports, is an IP address, a key, and a signature scheme indicator used to interpret the key. These eight pieces of information are conveyed to the kernel via a json file, known as the connection file.
In today’s JKG implementation, the IP address must be a local IP address meaning that the kernel cannot be remote from the kernel gateway. The enforcement of this restriction is down in the jupyter_client module - two levels below JKG.
This component is the core communication mechanism between the Notebook and the kernel. All aspects, including life-cycle management, can occur via this component. The kernel process (below) comes into play only when port-based communication becomes unreliable or additional information is required.
Kernel Process¶
When a kernel is launched, one of the fields of the kernel’s associated kernel specification is used to
identify a command to invoke. In today’s implementation, this command information, along with other
environment variables (also described in the kernel specification), is passed to popen() which returns
a process class. This class supports four basic methods following its creation:
poll()to determine if the process is still runningwait()to block the caller until the process has terminatedsend_signal(signum)to send a signal to the processkill()to terminate the process
As you can see, other forms of process communication can be achieved by abstracting the launch mechanism.
Remote Kernel Spec¶
The primary vehicle for indicating a given kernel should be handled in a different manner is the kernel
specification, otherwise known as the kernel spec. Enterprise Gateway introduces a new subclass of KernelSpec
named RemoteKernelSpec.
The RemoteKernelSpec class provides support for a new (and optional) stanza within the kernelspec file. This
stanza is named process_proxy and identifies the class that provides the kernel’s process abstraction (while
allowing for future extensions).
Here’s an example of a kernel specification that uses the DistributedProcessProxy class for its abstraction:
{
"language": "scala",
"display_name": "Spark 2.1 - Scala (YARN Client Mode)",
"process_proxy": {
"class_name": "enterprise_gateway.services.processproxies.distributed.DistributedProcessProxy"
},
"env": {
"SPARK_HOME": "/usr/hdp/current/spark2-client",
"__TOREE_SPARK_OPTS__": "--master yarn --deploy-mode client --name ${KERNEL_ID:-ERROR__NO__KERNEL_ID}",
"__TOREE_OPTS__": "",
"LAUNCH_OPTS": "",
"DEFAULT_INTERPRETER": "Scala"
},
"argv": [
"/usr/local/share/jupyter/kernels/spark_2.1_scala_yarn_client/bin/run.sh",
"--profile",
"{connection_file}",
"--RemoteProcessProxy.response-address",
"{response_address}"
]
}
The RemoteKernelSpec class definition can be found in
remotekernelspec.py
See the Process Proxy section for more details.
Remote Mapping Kernel Manager¶
RemoteMappingKernelManager is a subclass of JKG’s existing SeedingMappingKernelManager and provides two functions.
- It provides the vehicle for making the
RemoteKernelManagerclass known and available. - It overrides
start_kernelto look at the target kernel’s kernel spec to see if it contains a remote process proxy class entry. If so, it records the name of the class in its member variable to be made avaiable to the kernel start logic.
Remote Kernel Manager¶
RemoteKernelManager is a subclass of JKG’s existing KernelGatewayIOLoopKernelManager class and provides the
primary integration points for remote process proxy invocations. It implements a number of methods which allow
Enterprise Gateway to circumvent functionality that might otherwise be prevented. As a result, some of these overrides may
not be necessary if lower layers of the Jupyter framework were modified. For example, some methods are required
because Jupyter makes assumptions that the kernel process is local.
Its primary functionality, however, is to override the _launch_kernel method (which is the method closest to
the process invocation) and instantiates the appropriate process proxy instance - which is then returned in
place of the process instance used in today’s implementation. Any interaction with the process then takes
place via the process proxy.
Both RemoteMappingKernelManager and RemoteKernelManager class definitions can be found in
remotemanager.py
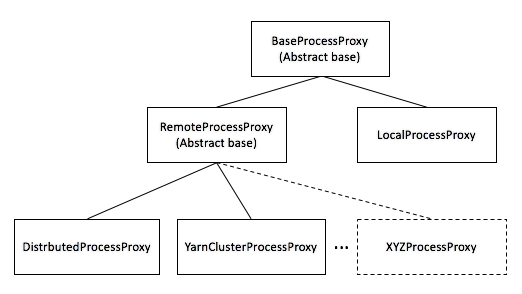
Process Proxy¶
Process proxy classes derive from the abstract base class BaseProcessProxyABC - which defines the four basic
process methods. There are two immediate subclasses of BaseProcessProxyABC - LocalProcessProxy
and RemoteProcessProxy.
LocalProcessProxy is essentially a pass-through to the current implementation. KernelSpecs that do not contain
a process_proxy stanza will use LocalProcessProxy.
RemoteProcessProxy is an abstract base class representing remote kernel processes. Currently, there are two
built-in subclasses of RemoteProcessProxy - DistributedProcessProxy - representing a proof of concept
class that remotes a kernel via ssh and YarnClusterProcessProxy - representing the design target of launching
kernels hosted as yarn applications via yarn/cluster mode. These class definitions can be found in
processproxies package.
The process proxy constructor looks as follows:
def __init__(self, kernel_manager):
where
kernel_manageris an instance of aRemoteKernelManagerclass that is associated with the correspondingRemoteKernelSpecinstance.
@abstractmethod
def launch_process(self, kernel_cmd, *kw):
where
kernel_cmdis a list (argument vector) that should be invoked to launch the kernel. This parameter is an artifact of the kernel manager_launch_kernel()method.**kwis a set key-word arguments.
The launch_process() method is the primary method exposed on the Process Proxy classes. It’s responsible for
performing the appropriate actions relative to the target type. The process must be in a running state prior
to returning from this method - otherwise attempts to use the connections will not be successful since the
(remote) kernel needs to have created the sockets.
All process proxy subclasses should ensure BaseProcessProxyABC.launch_process() is called - which will automatically
place a variable named KERNEL_ID (consisting of the kernel’s unique ID) into the corresponding kernel’s environment
variable list since KERNEL_ID is a primary mechanism for associating remote applications to a specific kernel instance.
def poll(self):
The poll() method is used by the Jupyter framework to determine if the process is still alive. By default, the
framework’s heartbeat mechanism calls poll() every 3 seconds. This method returns None if the process is still running, False otherwise (per the popen() contract).
def wait(self):
The wait() method is used by the Jupyter framework when terminating a kernel. Its purpose is to block return
to the caller until the process has terminated. Since this could be a while, its best to return control in a
reasonable amount of time since the kernel instance is destroyed anyway. This method does not return a value.
def send_signal(self, signum):
The send_signal() method is used by the Jupyter framework to send a signal to the process. Currently, SIGINT (2)
(to interrupt the kernel) is the signal sent.
It should be noted that for normal processes - both local and remote - poll() and kill() functionality can
be implemented via send_signal with signum values of 0 and 9, respectively.
This method returns None if the process is still running, False otherwise.
def kill(self):
The kill() method is used by the Jupyter framework to terminate the kernel process. This method is only necessary
when the request to shutdown the kernel - sent via the control port of the zero-MQ ports - does not respond in
an appropriate amount of time.
This method returns None if the process is killed successfully, False otherwise.
RemoteProcessProxy¶
As noted above, RemoteProcessProxy is an abstract base class that derives from BaseProcessProxyABC. Subclasses
of RemoteProcessProxy must implement two methods - confirm_remote_startup() and handle_timeout():
@abstractmethod
def confirm_remote_startup(self, kernel_cmd, **kw):
where
kernel_cmdis a list (argument vector) that should be invoked to launch the kernel. This parameter is an artifact of the kernel manager_launch_kernel()method.**kwis a set key-word arguments.
confirm_remote_startup() is responsible for detecting that the remote kernel has been appropriately launched and is
ready to receive requests. This can include gather application status from the remote resource manager but is really
a function of having received the connection information from the remote kernel launcher. (See Launchers)
@abstractmethod
def handle_timeout(self):
handle_timeout() is responsible for detecting that the remote kernel has failed to startup in an acceptable time. It
should be called from confirm_remote_startup(). If the timeout expires, handle_timeout() should throw HTTP
Error 500 (Internal Server Error).
Kernel launch timeout expiration is expressed via the environment variable KERNEL_LAUNCH_TIMEOUT. If this
value does not exist, it defaults to the Enterprise Gateway process environment variable EG_KERNEL_LAUNCH_TIMEOUT - which
defaults to 30 seconds if unspecified. Since all KERNEL_ environment variables “flow” from NB2KG, the launch
timeout can be specified as a client attribute of the Notebook session.
Launchers¶
As noted above a kernel is considered started once the launcher has conveyed its connection information back to the Enterprise Gateway server process. Conveyance of connection information from a remote kernel is the responsibility of the remote kernel launcher.
Launchers provide a means of normalizing behaviors across kernels while avoiding kernel modifications.Besides providing a location where connection file creation can occur, they also provide a ‘hook’ for other kinds of behaviors - like establishing virtual environments or sandboxes, providing collaboration behavior, etc.
There are three primary tasks of a launcher:
- Creation of the connection file on the remote (target) system
- Conveyance of the connection information back to the Enterprise Gateway process
- Invocation of the target kernel
Launchers are minimally invoked with two parameters (both of which are conveyed by the argv stanza of the
corresponding kernel.json file) - a path to the non-existent connection file represented by the
placeholder {connection_file} and a response address consisting of the Enterprise Gateway server IP and port on which
to return the connection information similarly represented by the placeholder {response_address}.
Depending on the target kernel, the connection file parameter may or may not be identified by an
argument name. However, the response address is identified by the parameter --RemoteProcessProxy.response_address. Its
value ({response_address}) consists of a string of the form <IPV4:port> where the IPV4 address points
back to the Enterprise Gateway server - which is listening for a response on the provided port.
Here’s a kernel.json file illustrating these parameters…
{
"language": "python",
"display_name": "Spark 2.1 - Python (YARN Cluster Mode)",
"process_proxy": {
"class_name": "enterprise_gateway.services.processproxies.yarn.YarnClusterProcessProxy"
},
"env": {
"SPARK_HOME": "/usr/hdp/current/spark2-client",
"SPARK_OPTS": "--master yarn --deploy-mode cluster --name ${KERNEL_ID:-ERROR__NO__KERNEL_ID} --conf spark.yarn.submit.waitAppCompletion=false",
"LAUNCH_OPTS": ""
},
"argv": [
"/usr/local/share/jupyter/kernels/spark_2.1_python_yarn_cluster/bin/run.sh",
"{connection_file}",
"--RemoteProcessProxy.response-address",
"{response_address}"
]
}
Kernel.json files also include a LAUNCH_OPTS: section in the env stanza to allow for custom
parameters to be conveyed in the launcher’s environment. LAUNCH_OPTS are then referenced in
the run.sh
script as the initial arguments to the launcher
(see launch_ipykernel.py) …
eval exec \
"${SPARK_HOME}/bin/spark-submit" \
"${SPARK_OPTS}" \
"${PROG_HOME}/scripts/launch_ipykernel.py" \
"${LAUNCH_OPTS}" \
"$@"
Extending Enterprise Gateway¶
Theoretically speaking, enabling a kernel for use in other frameworks amounts to the following:
- Build a kernel specification file that identifies the process proxy class to be used.
- Implement the process proxy class such that it supports the four primitive functions of
poll(),wait(),send_signal(signum)andkill()along withlaunch_process(). - If the process proxy corresponds to a remote process, derive the process proxy class from
RemoteProcessProxyand implementconfirm_remote_startup()andhandle_timeout(). - Insert invocation of a launcher (if necessary) which builds the connection file and
returns its contents on the
{response_address}socket.